并发编程的bug源头
在我们开发过程中,会经常使用并发编程,同时也会出现和我们预期不一样的问题,那么这些问题是如何产生的呢?
源头之⼀:缓存导致的可⻅性问题
在单核时代,所有的线程都是在⼀颗 CPU 上执⾏,CPU 缓存与内存的数据⼀致性容易解 决。因为所有线程都是操作同⼀个 CPU 的缓存,⼀个线程对缓存的写,对另外⼀个线程来 说⼀定是可⻅的。
⼀个线程对共享变量的修改,另外⼀个线程能够⽴刻看到,我们称为可⻅性。
多核时代,每颗 CPU 都有⾃⼰的缓存,这时 CPU 缓存与内存的数据⼀致性就没那么容易 解决了,当多个线程在不同的 CPU 上执⾏时,这些线程操作的是不同的 CPU 缓存。⽐如 下图中,线程 A 操作的是 CPU-1 上的缓存,⽽线程 B 操作的是 CPU-2 上的缓存,很明 显,这个时候线程 A 对变量 V 的操作对于线程 B ⽽⾔就不具备可⻅性了。这个就属于硬件 程序员给软件程序员挖的坑。
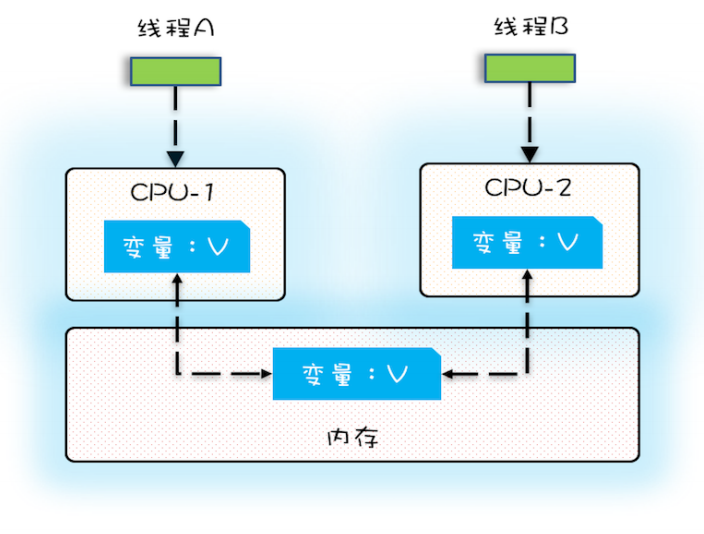
下⾯我们再⽤⼀段代码来验证⼀下多核场景下的可⻅性问题。下⾯的代码,每执⾏⼀次 add10K() ⽅法,都会循环 10000 次 count+=1 操作。在 calc() ⽅法中我们创建了两个线 程,每个线程调⽤⼀次 add10K() ⽅法,我们来想⼀想执⾏ calc() ⽅法得到的结果应该是多 少呢?
public class Test {
private long count = 0;
private void add10K() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
public static long calc() {
final Test test = new Test();
// 创建两个线程,执⾏add()操作
Thread th1 = new Thread(()->{ test.add10K(); });
Thread th2 = new Thread(()->{ test.add10K(); });
// 启动两个线程
th1.start(); th2.start();
// 等待两个线程执⾏结束
th1.join();
th2.join();
return count;
}
}
直觉告诉我们应该是 20000,因为在单线程⾥调⽤两次 add10K() ⽅法,count 的值就是 20000,但实际上 calc() 的执⾏结果是个 10000 到 20000 之间的随机数。为什么呢?
我们假设线程 A 和线程 B 同时开始执⾏,那么第⼀次都会将 count=0 读到各⾃的 CPU 缓 存⾥,执⾏完 count+=1 之后,各⾃ CPU 缓存⾥的值都是 1,同时写⼊内存后,我们会发 现内存中是 1,⽽不是我们期望的 2。之后由于各⾃的 CPU 缓存⾥都有了 count 的值,两 个线程都是基于 CPU 缓存⾥的 count 值来计算,所以导致最终 count 的值都是⼩于 20000 的。这就是缓存的可⻅性问题。
源头之⼆:线程切换带来的原⼦性问题
由于 IO 太慢,早期的操作系统就发明了多进程,即便在单核的 CPU 上我们也可以⼀边听 着歌,⼀边写 Bug,这个就是多进程的功劳。
操作系统允许某个进程执⾏⼀⼩段时间,例如 50 毫秒,过了 50 毫秒操作系统就会重新选 择⼀个进程来执⾏(我们称为“任务切换”),这个 50 毫秒称为“时间⽚”。
下图是线程切换示意图 :
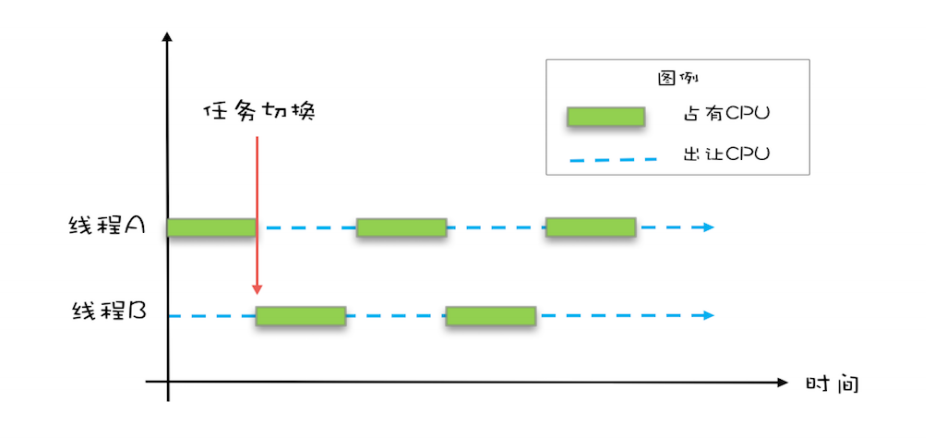
在⼀个时间⽚内,如果⼀个进程进⾏⼀个 IO 操作,例如读个⽂件,这个时候该进程可以把 ⾃⼰标记为“休眠状态”并出让 CPU 的使⽤权,待⽂件读进内存,操作系统会把这个休眠的 进程唤醒,唤醒后的进程就有机会重新获CPU 的使⽤权了。
这⾥的进程在等待 IO 时之所以会释放 CPU 使⽤权,是为了让 CPU 在这段等待时间⾥可 以做别的事情,这样⼀来 CPU 的使⽤率就上来了;此外,如果这时有另外⼀个进程也读⽂ 件,读⽂件的操作就会排队,磁盘驱动在完成⼀个进程的读操作后,发现有排队的任务,就 会⽴即启动下⼀个读操作,这样 IO 的使⽤率也上来了。
Java 并发程序都是基于多线程的,⾃然也会涉及到任务切换,也许你想不到,任务切换竟 然也是并发编程⾥诡异 Bug 的源头之⼀。任务切换的时机⼤多数是在时间⽚结束的时候, 我们现在基本都使⽤⾼级语⾔编程,⾼级语⾔⾥⼀条语句往往需要多条 CPU 指令完成,例 如上⾯代码中的count += 1,⾄少需要三条 CPU 指令。
- 指令 1:⾸先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执⾏ +1 操作;
- 指令 3:最后,将结果写⼊内存(缓存机制导致可能写⼊的是 CPU 缓存⽽不是内存)。
我们潜意识⾥⾯觉得 count+=1 这个操作是⼀个不可分割的整体,就像⼀个原⼦⼀样,线程 的切换可以发⽣在 count+=1 之前,也可以发⽣在 count+=1 之后,但就是不会发⽣在中 间。
我们把⼀个或者多个操作在 CPU 执⾏的过程中不被中断的特性称为原⼦性。CPU 能 保证的原⼦操作是 CPU 指令级别的,⽽不是⾼级语⾔的操作符,这是违背我们直觉的地 ⽅。因此,很多时候我们需要在⾼级语⾔层⾯保证操作的原⼦性。
源头之三:编译优化带来的有序性问题
那并发编程⾥还有没有其他有违直觉容易导致诡异 Bug 的技术呢?有的,就是有序性。顾 名思义,有序性指的是程序按照代码的先后顺序执⾏。编译器为了优化性能,有时候会改变 程序中语句的先后顺序,例如程序中:
“a=6;b=7;”
编译器优化后可能变成
“b=7; a=6;”
在这个例⼦中,编译器调整了语句的顺序,但是不影响程序的最终结果。不过有 时候编译器及解释器的优化可能导致意想不到的 Bug。
小结
要写好并发程序,⾸先要知道并发程序的问题在哪⾥,只有确定了“靶⼦”,才有可能把问 题解决,毕竟所有的解决⽅案都是针对问题的。并发程序经常出现的诡异问题看上去⾮常⽆ 厘头,但是深究的话,⽆外乎就是直觉欺骗了我们,只要我们能够深刻理解可⻅性、原⼦ 性、有序性在并发场景下的原理,很多并发 Bug 都是可以理解、可以诊断的。
在介绍可⻅性、原⼦性、有序性的时候,特意提到缓存导致的可⻅性问题,线程切换带来的 原⼦性问题,编译优化带来的有序性问题,其实缓存、线程、编译优化的⽬的和我们写并发 程序的⽬的是相同的,都是提⾼程序性能。但是技术在解决⼀个问题的同时,必然会带来另 外⼀个问题,所以在采⽤⼀项技术的同时,⼀定要清楚它带来的问题是什么,以及如何规 避。
文档信息
- 本文作者:yindongxu
- 本文链接:https://iceblow.github.io/2020/02/01/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B01-bug%E6%BA%90%E5%A4%B4/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)