在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识,此时一个能够生成全局唯一ID的系统是非常必要的。
UUID
生成分布式id的算法有多种,常见的有UUID,它包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000
优点:
- 性能非常高:本地生成,没有网络消耗。
缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露
- ID作为主键时或者索引都太长了,且是无序的。
雪花算法
下面我们重点介绍在实际开发场景中,用到最多的雪花算法,下图是雪花算法id分段图,64位long型数据。
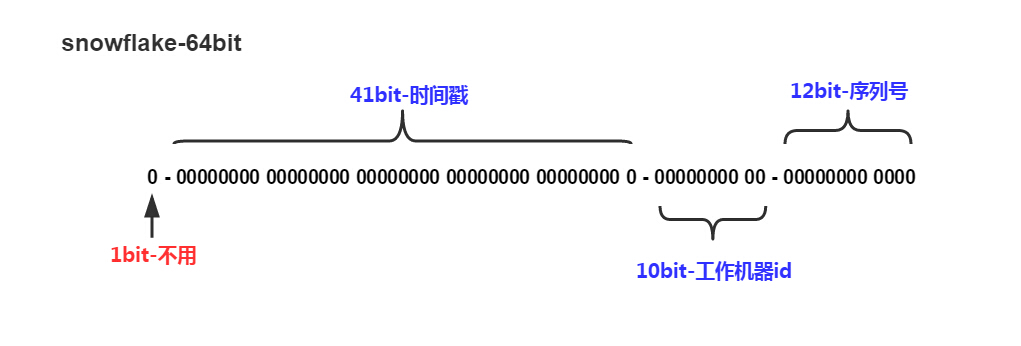
1bit-不用:最高位,代表符号位,为0;
41bit-时间戳:可以表示(1L«41)/(1000L360024*365)=69年的时间,这里的时间是系统当前时间 - 起始时间(自定义);
10bit-机器id:可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义;
12bit-序列号:表示2^12个ID,每毫秒最多生成4096个序列号,理论上snowflake方案的QPS约为409.6w/s。
这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的,最后生成的是长度18的long型数据。
public class SnowFlake {
// 起始的时间戳
private final static long START_STMP = 1577808000000L; //2020-01-01
// 每一部分占用的位数,就三个
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5; //数据中心占用的位数
// 每一部分最大值
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
// 每一部分向左的位移
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L; //上一次时间戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
//产生下一个ID
public synchronized long nextId() {
long currStmp = timeGen();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//if条件里表示当前调用和上一次调用落在了相同毫秒内,只能通过第三部分,序列号自增来判断为唯一,所以+1.
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大,只能等待下一个毫秒
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
//执行到这个分支的前提是currTimestamp > lastTimestamp,说明本次调用跟上次调用对比,已经不再同一个毫秒内了,这个时候序号可以重新回置0了。
sequence = 0L;
}
lastStmp = currStmp;
//就是用相对毫秒数、机器ID和自增序号拼接
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = timeGen();
while (mill <= lastStmp) {
mill = timeGen();
}
return mill;
}
private long timeGen() {
return System.currentTimeMillis();
}
}
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
文档信息
- 本文作者:yindongxu
- 本文链接:https://iceblow.github.io/2021/10/17/%E9%9B%AA%E8%8A%B1%E7%AE%97%E6%B3%95/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)