面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。
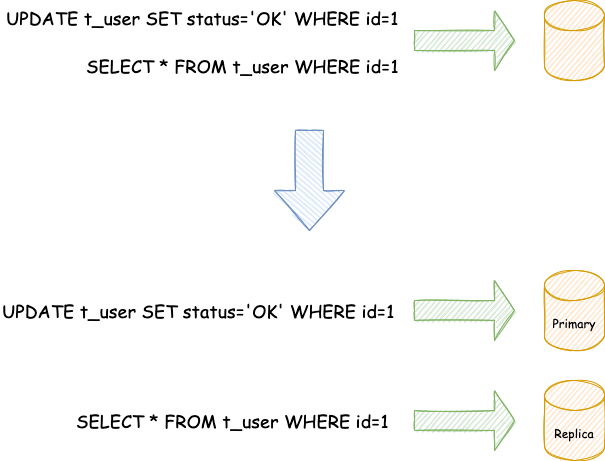
读写分离的数据节点中的数据内容是一致的,而水平分片的每个数据节点的数据内容却并不相同。将水平分片和读写分离联合使用,能够更加有效的提升系统性能。
中间件
读写分离的中间件常见有canal、altas、sharding-jdbc等,下面我们只讲sharding-jdbc,原理差不多。以下是sharding-jdbc读写分离的基本概念。
主库
添加、更新以及删除数据操作所使用的数据库,sharding-jdbc目前仅支持单主库。
从库
查询数据操作所使用的数据库,可支持多从库。
主从同步
将主库的数据异步的同步到从库的操作。 由于主从同步的异步性,从库与主库的数据会短时间内不一致。
负载均衡策略
通过负载均衡策略将查询请求疏导至不同从库,常见的有轮询策略和随机策略。
支持项
- 提供一主多从的读写分离配置,可独立使用,也可配合数据分片使用;
- 事务中的数据读写均用主库;
- 基于 Hint 的强制主库路由
不支持项
- 主库和从库的数据同步,需要借助其它中间件进行同步
- 主库和从库的数据同步延迟导致的数据不一致;
- 主库多写;
- 主从库间的事务一致性。主从模型中,事务中的数据读写均用主库。
存在的问题
读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题。 这包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。
并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。
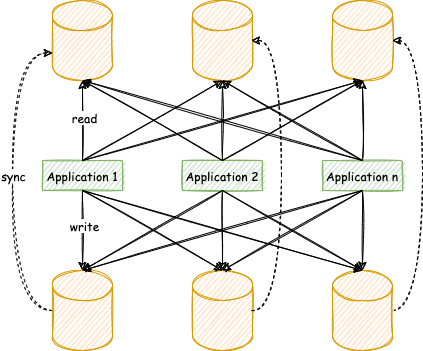
下图展现了将数据分片与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系。
Demo分享
本地搭建了一个demo,使用了sharding-jdbc中间件,实现了读写分离功能,数据同步是本地库触发器实现的。
pom依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- sharding 4.0 ,版本不同yml配置也不同,见官网配置-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!-- mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>
<!--阿里数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.14</version>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.60</version>
</dependency>
</dependencies>
yml配置
数据源使用了1主2从配置,主库是master,用于写。从库是slave1,slave2,用于读,负载均衡策略是轮询。
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names:
master,slave1,slave2
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/demo_master?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: root
# 从库1
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/demo_slave?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: root
#从库2
slave2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/demo_slave_2?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: root
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave1,slave2
props:
# 开启SQL显示,默认false
sql:
show: true
建表SQL
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) DEFAULT NULL COMMENT '名称',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1462719262060716034 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
由于mysql开启binlog主从同步配置需要不同的ip,本地数据库使用了触发器同步主库的数据到从库。
CREATE DEFINER=`root`@`localhost` TRIGGER `insert_user` AFTER INSERT ON `user` FOR EACH ROW BEGIN
INSERT INTO demo_slave.`user`(id,`name`,age,create_time) VALUES (new.id,new.`name`,new.age,new.create_time);
INSERT INTO demo_slave_2.`user`(id,`name`,age,create_time) VALUES (new.id,new.`name`,new.age,new.create_time);
END;
Controller层
@RestController
@RequestMapping("user")
public class UserController {
@Resource
private UserService userService;
// 新增
@PostMapping("/add")
public long saveUser() {
User entity = new User();
entity.setName("test");
entity.setAge(19);
entity.setCreateTime(new Date());
userService.save(entity);
return entity.getId();
}
// 查询
@GetMapping("/query/{id}")
public User query(@PathVariable long id) {
User user = userService.getById(id);
return user;
}
}
服务启动后,日志显示3个连接池初始化。
com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
com.alibaba.druid.pool.DruidDataSource : {dataSource-2} inited
com.alibaba.druid.pool.DruidDataSource : {dataSource-3} inited
接口测试
首先,调用新增接口,使用的是master库写入。
SQL: INSERT INTO user ( id,
create_time,
name,
age ) VALUES ( ?,
?,
?,
? ) ::: DataSources: master
然后,多次调用查询接口,slave1和slave2轮询调用。
ShardingSphere-SQL : Rule Type: master-slave
SQL: SELECT id,create_time,name,age FROM user WHERE id=? ::: DataSources: slave1
SQL: SELECT id,create_time,name,age FROM user WHERE id=? ::: DataSources: slave2
SQL: SELECT id,create_time,name,age FROM user WHERE id=? ::: DataSources: slave1
SQL: SELECT id,create_time,name,age FROM user WHERE id=? ::: DataSources: slave2
强制查询主库
如果对实时性要求高的接口,必须立即返回最新的数据,那么就不能查询从库,sharding-jdbc提供了查询主库的方法类HintManager,
HintManager hintManager = HintManager.getInstance(); hintManager.setMasterRouteOnly();
@GetMapping("/query/{id}")
public User query(@PathVariable long id) {
// 强制主库查询
HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();
User user = userService.getById(id);
return user;
}
文档信息
- 本文作者:yindongxu
- 本文链接:https://iceblow.github.io/2021/11/22/%E8%AF%BB%E5%86%99%E5%88%86%E7%A6%BB/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)