传统的将数据集中存储至单一节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足海量数据的场景。
从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降; 同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
从可用性的方面来讲,服务化的无状态型,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。 而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。 数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。
背景概括
- 性能差:数据量过大和高并发情况下查询性能瓶颈
- 可用性:系统压力在数据库,单一节点不能水平扩展
- 运维成本高:数据备份和恢复时间成本高
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
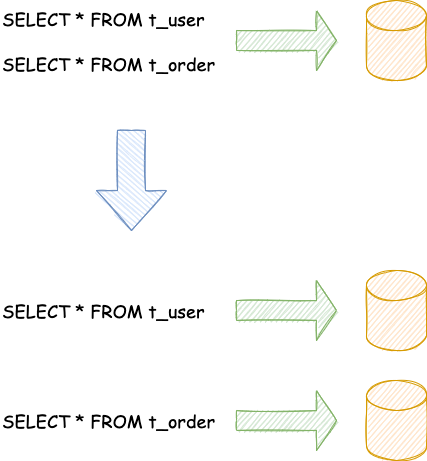
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。
垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
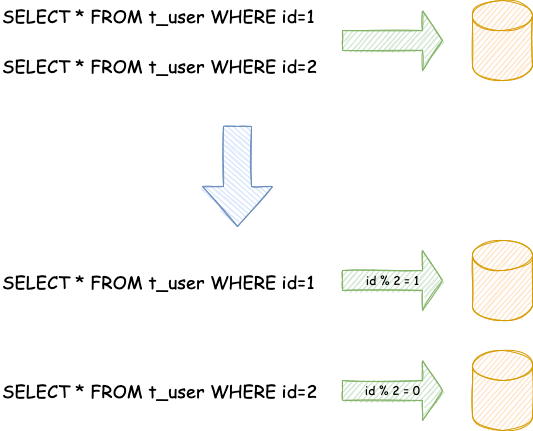
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
挑战
虽然数据分片解决了性能、可用性以及单点备份恢复等问题,但分布式的架构在获得了收益的同时,也引入了新的问题。
面对如此散乱的分片之后的数据,应用开发工程师和数据库管理员对数据库的操作变得异常繁重就是其中的重要挑战之一。 他们需要知道数据需要从哪个具体的数据库的子表中获取。
另一个挑战则是,能够正确的运行在单节点数据库中的 SQL,在分片之后的数据库中并不一定能够正确运行。 例如,分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理。
跨库事务也是分布式的数据库集群要面对 的棘手事情。 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。
在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA 的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
核心概念
下面主要介绍sharding-jdbc数据分片的核心概念。
表
表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
真实表
在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9。
绑定表
指分片规则一致的主表和子表。 例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。 因此,绑定表间的分区键需要完全相同。
广播表
指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
单表
指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
数据节点
数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0。
逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
均匀分布
指数据表在每个数据源内呈现均匀分布的态势, 例如:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
自定义分布
指数据表呈现有特定规则的分布, 例如:
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
分片
分片键
用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。
除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
分片算法
用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。
分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
自动化分片算法
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
自定义分片算法
提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
- 标准分片算法
用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
- 复合分片算法
用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
- Hint 分片算法
用于处理使用 Hint 行分片的场景。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
强制分片路由
对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。 例:按照员工登录主键分库,而数据库中并无此字段。
SQL Hint 支持通过 Java API 和 SQL 注释(待实现)两种方式使用。 详情请参见强制分片路由。
行表达式
配置的简化与一体化是行表达式所希望解决的两个主要问题。
在繁琐的数据分片规则配置中,随着数据节点的增多,大量的重复配置使得配置本身不易被维护。 通过行表达式可以有效地简化数据节点配置工作量。
对于常见的分片算法,使用 Java 代码实现并不有助于配置的统一管理。 通过行表达式书写分片算法,可以有效地将规则配置一同存放,更加易于浏览与存储。
语法说明
行表达式的使用非常直观,只需要在配置中使用 ${ expression } 或 $->{ expression } 标识行表达式即可。 目前支持数据节点和分片算法这两个部分的配置。 行表达式的内容使用的是 Groovy 的语法,Groovy 能够支持的所有操作,行表达式均能够支持。 例如:
${begin..end} 表示范围区间
${[unit1, unit2, unit_x]} 表示枚举值
行表达式中如果出现连续多个 ${ expression } 或 $->{ expression } 表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
配置
数据节点
对于均匀分布的数据节点,如果数据结构如下:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
用行表达式可以简化为:
db$->{0..1}.t_order$->{0..1}
对于自定义的数据节点,如果数据结构如下:
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
用行表达式可以简化为:
db0.t_order$->{0..1},db1.t_order$->{2..4}
分片算法
对于只有一个分片键的使用 = 和 IN 进行分片的 SQL,可以使用行表达式代替编码方式配置。
行表达式内部的表达式本质上是一段 Groovy 代码,可以根据分片键进行计算的方式,返回相应的真实数据源或真实表名称。
例如:分为 10 个库,尾数为 0 的路由到后缀为 0 的数据源, 尾数为 1 的路由到后缀为 1 的数据源,以此类推。用于表示分片算法的行表达式为:
ds$->{id % 10}
分布式主键
目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。
为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
其中雪花算法的原理本文就不讲解了,重点说下对时钟回拨的处理。
时钟回拨
服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。
如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;
如果在可容忍的范围内,默认主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为 0,可通过属性设置。
强制分片路由
通过解析 SQL 语句提取分片键列与值并进行分片是 Apache ShardingSphere 对 SQL 零侵入的实现方式。 若 SQL 语句中没有分片条件,则无法进行分片,需要全路由。
在一些应用场景中,分片条件并不存在于 SQL,而存在于外部业务逻辑。 因此需要提供一种通过外部指定分片结果的方式,在 Apache ShardingSphere 中叫做 Hint。
实现机制
Apache ShardingSphere 使用 ThreadLocal 管理分片键值。 可以通过编程的方式向 HintManager 中添加分片条件,该分片条件仅在当前线程内生效。
除了通过编程的方式使用强制分片路由,Apache ShardingSphere 还计划通过 SQL 中的特殊注释的方式引用 Hint,使开发者可以采用更加透明的方式使用该功能。
指定了强制分片路由的 SQL 将会无视原有的分片逻辑,直接路由至指定的真实数据节点。
文档信息
- 本文作者:yindongxu
- 本文链接:https://iceblow.github.io/2021/12/03/%E6%95%B0%E6%8D%AE%E5%BA%93%E5%88%86%E7%89%87-%E5%9F%BA%E7%A1%80%E7%AF%87/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)