上篇文章我们已经讲述了数据库分片的理论基础,为了更直观的看到结果,本文实战篇会帖上代码和相关配置。
我们使用sharding-jdbc中间件进行分库分表,版本4.0,关于使用的详细配置可以查看官网的说明。
SQL准备
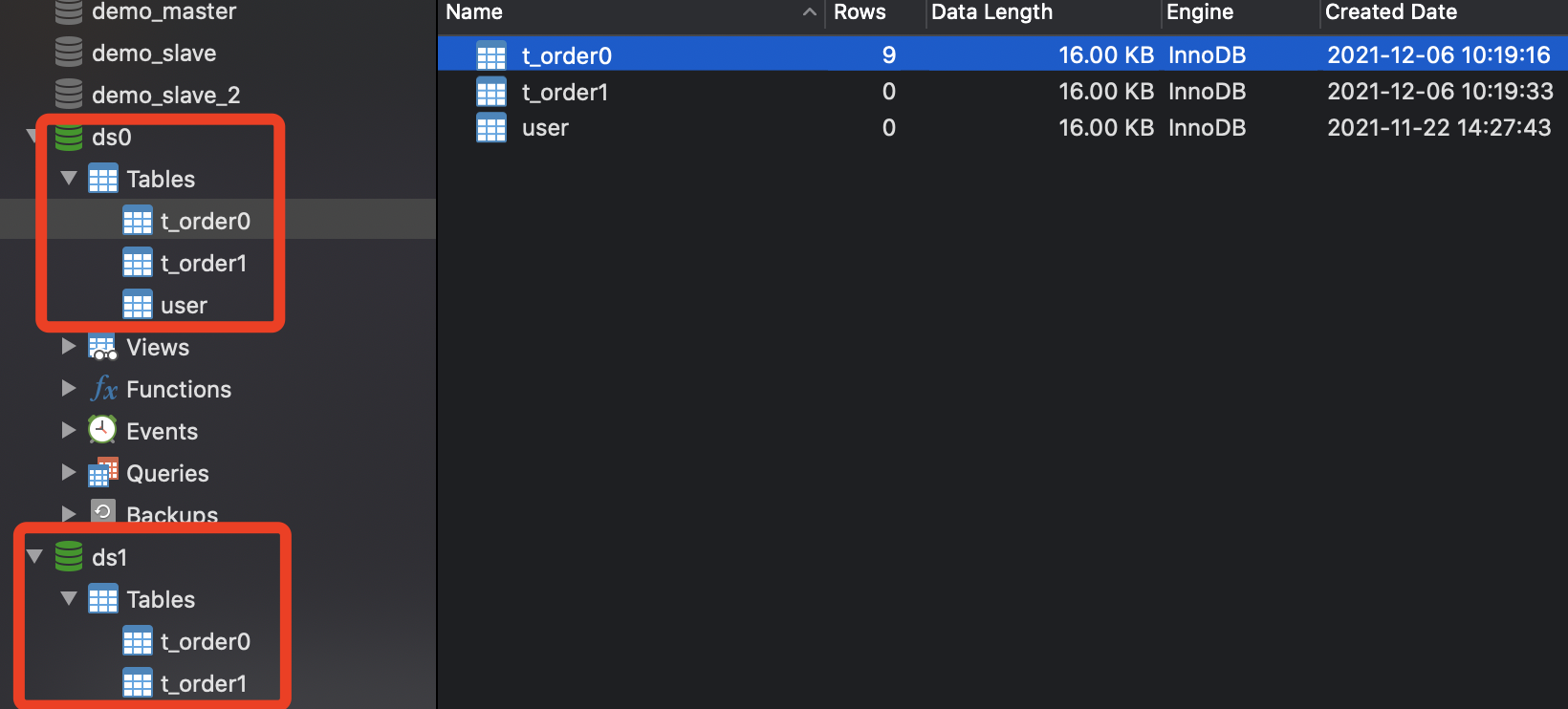
本次测试我们有两张表,t_order表(分库分表)和user表(不分库分表),为演示用,user表和t_order表使用同一个实例。
mysql数据库有2个实例,数据源ds0和ds1。
t_order水平拆分2个库,2个表,根据userId分片,
分片逻辑:
userId取模选择库:userId % 2,结果为0的落在ds0,结果为1的落在ds1
userId先除取整再取模 (userId / 2)% 2,结果为0的在t_order0,结果为1的在t_order1
user表不分库分表,只落在ds0库,1个单表。
以下是建表语句:
CREATE TABLE `t_order` (
`order_id` bigint(20) NOT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL COMMENT '主键',
`name` varchar(255) DEFAULT NULL COMMENT '名称',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
最终在Navicat查看已经建表成功。
Java代码
pom依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- sharding -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!-- mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>
<!--阿里数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.14</version>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.60</version>
</dependency>
</dependencies>
yml配置
#分库分表,订单=2库*2表
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
dataSource:
names: ds0,ds1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: root
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: root
sharding:
tables:
t_order:
actualDataNodes: ds${0..1}.t_order${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: user_id
algorithmExpression: t_order${(int)(user_id / 2) % 2}
user:
actualDataNodes: ds0.user
props:
# 开启SQL显示,默认false
sql:
show: true
api接口
接口包括新增接口、userId查询订单接口,orderId查询订单接口等。
新增订单
// 新增
@PostMapping("/add")
public long save() {
SnowFlakeUtil util = new SnowFlakeUtil(1, 1);
List<Order> orders = new LinkedList<>();
// 批量插入多条, userId多个
for (int i = 0; i < 12; i++) {
Order entity = new Order();
entity.setOrderId(util.nextId());
entity.setCreateTime(new Date());
entity.setUserId((long) i);
orders.add(entity);
}
orderService.saveBatch(orders);
return orders.size();
}
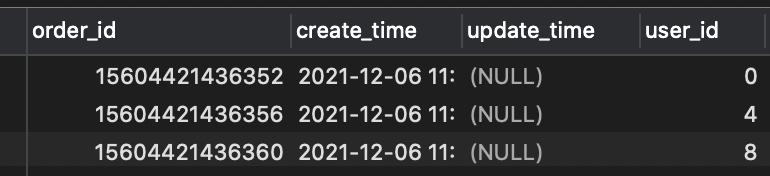
userId数据使用的是0~11共12条数据,这样每个表会有12/4=3条数据,新增结果如下:
- userId = 0,4,8落在ds0.t_order0表;
- userId = 2,6,10落在ds0.t_order1表;
- userId = 1,5,9落在ds1.t_order0表;
- userId = 3,7,11落在ds1.t_order1表。
userId查询订单
// userId查订单
@GetMapping("/query/userId/{userId}")
public List<Order> queryUserOrder(@PathVariable long userId) {
QueryWrapper<Order> wrapper = new QueryWrapper<>();
wrapper.eq("user_id", userId);
return orderService.list(wrapper);
}
因为userId是分片键,所以可以根据分片路由到指定库ds0.t_order0 (userId=0)
Actual SQL: ds0 ::: SELECT create_time,order_id,update_time,user_id FROM t_order0
WHERE (user_id = ?) ::: [0]
如果查询条件没有分片键呢?下面请看orderId查询订单。
orderId查询订单
// orderId查订单
@GetMapping("/query/{orderId}")
public Order query(@PathVariable long orderId) {
QueryWrapper<Order> wrapper = new QueryWrapper<>();
wrapper.eq("order_id", orderId);
Order entity = orderService.getOne(wrapper);
return entity;
}
因为我们没有对orderId分片,所以根据orderId能查到订单么?我们先看执行结果:
Actual SQL: ds0 ::: SELECT create_time,order_id,update_time,user_id FROM t_order0 WHERE (order_id = ?) ::: [15604421436355]
Actual SQL: ds0 ::: SELECT create_time,order_id,update_time,user_id FROM t_order1 WHERE (order_id = ?) ::: [15604421436355]
Actual SQL: ds1 ::: SELECT create_time,order_id,update_time,user_id FROM t_order0 WHERE (order_id = ?) ::: [15604421436355]
Actual SQL: ds1 ::: SELECT create_time,order_id,update_time,user_id FROM t_order1 WHERE (order_id = ?) ::: [15604421436355]
我们发现每个库的每个表都查询了一次,最后找到结果,这种情况就用了广播路由的全库表路由。
对于不携带分片键的SQL,则采取广播路由的方式。根据SQL类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这5种类型。
全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL和DML,以及DDL等。
userId范围查询订单
QueryWrapper<Order> wrapper = new QueryWrapper<>();
wrapper.ge("user_id", startUserId); //0
wrapper.le("user_id", endUserId); // 1
如果根据userId范围(0<=userId<=3)查询,由于标准分片算法只支持=和IN,所以会走全库表路由。
[
{
"orderId": 15604421436352,
"userId": 0,
"createTime": "2021-12-06T03:52:51.000+0000",
"updateTime": null
},
{
"orderId": 15604421436353,
"userId": 1,
"createTime": "2021-12-06T03:52:51.000+0000",
"updateTime": null
}
]
userId IN查询订单
我们查询条件使用IN
QueryWrapper<Order> wrapper = new QueryWrapper<>();
wrapper.in("user_id", userIds); // 0和1
结果发现,sharing-jdbc会根据userId的值分片到具体的库表,这样就不需要全库表路由了,只会路由到对应的库表,然后合并结果。
ds0 ::: SELECT create_time,order_id,update_time,user_id FROM t_order0
WHERE (user_id IN (?,?)) ::: [0, 1]
ds1 ::: SELECT create_time,order_id,update_time,user_id FROM t_order0
WHERE (user_id IN (?,?)) ::: [0, 1]
复合分片策略
上面我们使用的是行表达式分片策略,只支持单分片键,且只支持=和IN的分片操作。
如果我们需要多个分片键,又该如何处理呢?
sharding-jdbc也提供了复合分片策略,ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
在实际开发中,比如订单表,我们会经常查询用户的订单或者根据订单号查询订单,单分片键无法满足这种需求,这里就需要用到复合分片。
一般用户的id由雪花算法生成,订单id用雪花算法生成再拼接用户id的后2位,实际分片键有2个,一个是用户id,另一个是订单id,分片算法都是取分片键的后2位进行取模取整,实际上,分片键的本质还是用户id的后两位分片。这样SQL语句中,有订单id或用户id都可以达到分片的效果。
结语
本文简单了介绍了sharing-jdbc分库分表的基本用法,使用了标准分片算法,如果业务需要,可以自行实现分片算法。
后面文章会分析sharing-jdbc的架构,敬请期待。
文档信息
- 本文作者:yindongxu
- 本文链接:https://iceblow.github.io/2021/12/06/%E6%95%B0%E6%8D%AE%E5%BA%93%E5%88%86%E7%89%87-%E5%AE%9E%E6%88%98%E7%AF%87/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)