对于CAP理论,大家耳熟能详,大部分开发人员都能说个大概,但是对于细节的了解可能还是不到位的。
这是为什么呢?主要是因为这个理论过于抽象,不同的资料对 CAP 的详细定义有一些细微的差别,初学者还是会感到困惑。
CAP理论
CAP理论也有多个版本,我们选择其中的两个,并做简单的分析。
第一版
对于一个分布式计算系统,不可能同时满足一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三个设计约束。
第二版
在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
从上面可以看出,第二版的定义更加清晰,明确了CAP探讨的是互连并共享数据的分布式系统,并且关注的是读写操作,而不是分布式所有的功能。
这里的共享是指同一份数据在多个节点都有,但并不一定在所有节点都有,简单理解有数据复制的系统就是CAP应用的场景。
那我们就以第二版的定义对C、A、P详细分析下:
一致性(Consistency)
对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
可用性(Availability)
非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
分区容忍性(Partition Tolerance)
当出现网络分区后,系统能够继续“履行职责”。网络分区包括丢包、连接中断、网络拥塞等。
CAP应用
虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。
如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证 C,系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A 冲突了,因为 A 要求返回 no error 和 no timeout。因此,分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
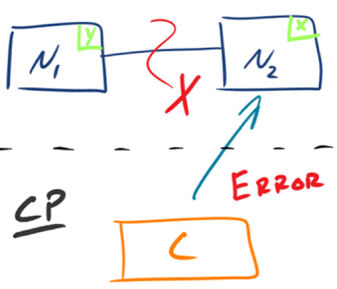
CP
如下图所示,为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
AP
如下图所示,为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。
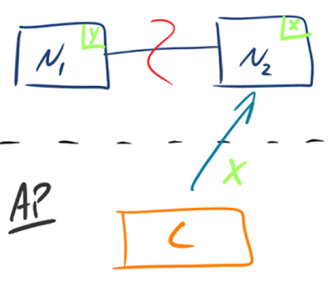
注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
CAP细节
CAP 关注的粒度是数据
CAP 理论的定义和解释中,用的都是 system、node 这类系统级的概念,这就给很多人造成了很大的误导,认为我们在进行架构设计时,整个系统要么选择 CP,要么选择 AP。
但在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据必须选择 CP,有的数据必须选择 AP。而如果我们做设计时,从整个系统的角度去选择 CP 还是 AP,就会发现顾此失彼,无论怎么做都是有问题的。
以一个最简单的用户管理系统为例,用户管理系统包含用户账号数据(用户 ID、密码)、用户信息数据(昵称、兴趣、爱好、性别、自我介绍等)。通常情况下,用户账号数据会选择 CP,而用户信息数据会选择 AP,如果限定整个系统为 CP,则不符合用户信息数据的应用场景;如果限定整个系统为 AP,则又不符合用户账号数据的应用场景。
所以在 CAP 理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(CP 还是 AP),而不是直接限定整个系统所有数据都是同一策略。
CAP 是忽略网络延迟的
这是一个非常隐含的假设,也就是说,当事务提交时,数据能够瞬间复制到所有节点。但实际情况下,从节点 A 复制数据到节点 B,总是需要花费一定时间的。这就意味着,CAP 理论中的 C 在实践中是不可能完美实现的,在数据复制的过程中,节点 A 和节点 B 的数据并不一致。
不要小看了这几毫秒或者几十毫秒的不一致,对于某些严苛的业务场景,例如和金钱相关的用户余额,或者和抢购相关的商品库存,技术上是无法做到分布式场景下完美的一致性的。而业务上必须要求一致性,因此单个用户的余额、单个商品的库存,理论上要求选择 CP 而实际上 CP 都做不到,只能选择 CA。也就是说,只能单点写入,其他节点做备份,无法做到分布式情况下多点写入。
需要注意的是,这并不意味着这类系统无法应用分布式架构,只是说“单个用户余额、单个商品库存”无法做分布式,但系统整体还是可以应用分布式架构的。
若不存在 CP 和 AP 的选择,可以选择 CA
CAP 理论告诉我们分布式系统只能选择 CP 或者 AP,但其实这里的前提是系统发生了“分区”现象。如果系统没有发生分区现象,也就是说 P 不存在的时候(节点间的网络连接一切正常),我们没有必要放弃 C 或者 A,应该 C 和 A 都可以保证,这就要求架构设计的时候既要考虑分区发生时选择 CP 还是 AP,也要考虑分区没有发生时如何保证 CA。
同样以用户管理系统为例,即使是实现 CA,不同的数据实现方式也可能不一样:用户账号数据可以采用“消息队列”的方式来实现 CA,因为消息队列可以比较好地控制实时性,但实现起来就复杂一些;而用户信息数据可以采用“数据库同步”的方式来实现 CA,因为数据库的方式虽然在某些场景下可能延迟较高,但使用起来简单。
放弃并不等于什么都不做,需要为分区恢复后做准备。
CAP 理论告诉我们三者只能取两个,需要“牺牲”(sacrificed)另外一个,这里的“牺牲”是有一定误导作用的,因为“牺牲”让很多人理解成什么都不做。实际上,CAP 理论的“牺牲”只是说在分区过程中我们无法保证 C 或者 A,但并不意味着什么都不做。
分区期间放弃 C 或者 A,并不意味着永远放弃 C 和 A,我们可以在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到 CA 的状态。最典型的就是在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到 CA 状态。
总结
CAP理论:必须是互连、共享数据的分布式系统,关注的是读写数据,假设忽略网络延迟,只能保证其中的两个。
文档信息
- 本文作者:yindongxu
- 本文链接:https://iceblow.github.io/2022/04/22/CAP%E7%90%86%E8%AE%BA/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)