面对高并发的场景,我们都会使用到Cache来缓存热点数据,避免高并发流量直接查询数据库,比如常用的分布式缓存Redis,用户请求的链路如下图:
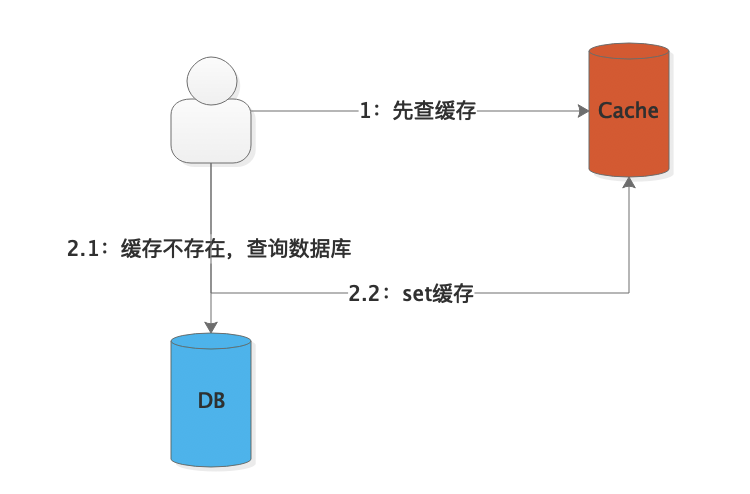
- 先查询缓存数据是否存在,如果存在,直接返回缓存数据;
- 如果缓存数据不存在(首次访问、key过期或被删除),再查询数据库,同步或异步保存到缓存,返回DB数据。
查询流程比较清晰,如果只涉及到查询,缓存和数据库的一致性还是可以保证的。
如果涉及到更新数据呢,尤其在高并发场景下,还能保证Cache和DB数据的一致性么?
业务更新数据,对缓存的处理情况主要是以下两种情况:
- 方案1:先删除Cache,在更新DB;
- 方案2:先更新DB,在删除Cache。
以上两种方案都会存在数据不一致,我们简单来分析下。
方案1:先删除Cache,在更新DB
在删除Cache后,读请求过来后,此时Cache数据不存在,只能从DB查询,此时查询到的是oldValue,然后更新DB为newValue,这样Cache和DB的数据存在不一致。
方案2:先更新DB,在删除Cache
先更新DB,如果此时该线程挂了,比如服务宕机或重启了,或者redis连接响应超时,无法删除Cache,此时的Cache还是oldValue,这样Cache和DB的数据也会存在不一致。
所以,删除Cache和更新DB并不是一个原子性操作,会存在很短的时间窗口,在面对高并发或者极端场景下,无法保证Cache和DB的一致性。
那么有没有方案能解决这个问题呢?
双删方案行不行?
网上有人提出双删方案,即先删除Cache,然后更新DB,最后再删除Cache。
对此方案个人并不认同,不明白先删除Cache的意义在哪里。第一次删除Cache后,此时如果有读请求,那么会缓存oldValue,更新DB后,此时缓存还是oldValue,第一次删除的作用呢?该方案不仅增加了一次删除缓存操作,同时在高并发的时候会查询至少两次DB(缓存删除后的读)和两次保存缓存数据,因此,该方案的第一次删除无意义。
个人思路
Cache和DB的数据一致性问题,我们可以类比参考CAP理论,假设Cache和DB是数据复制集的两个节点,但是只有DB单向到Cache的复制,考虑到分区容错性,可能会发生网络丢包、连接中断或者连接超时等故障,所以我们就要选择AP还是CP。
如果,我们要保证数据的强一致性,即选择CP,那么就必须牺牲系统的可用性,DB和缓存更新放在一个事务里,如果更新失败需要回滚,这样性能会有所下降,同时可能会出现更新失败的情况。
如果,我们要保证可用性,即选择AP,只能保证数据最终的一致性,允许短暂的时间窗内数据的不一致,同时借助其它中间件,来保证DB更新后,能最终更新到Cache。
来个可用的方案
上面的方案一和方案二相比较而言,方案二更靠谱,先更新DB,保证数据能落库,如果删除缓存失败了,我们还可以进行重试。
但是在极端情况下,如果服务宕机了,此时的线程无法执行后面的删除缓存操作,就一定会造成数据的不一致。
所以就需要引入其他中间件,比如Canal和MQ,方案流程如下图:
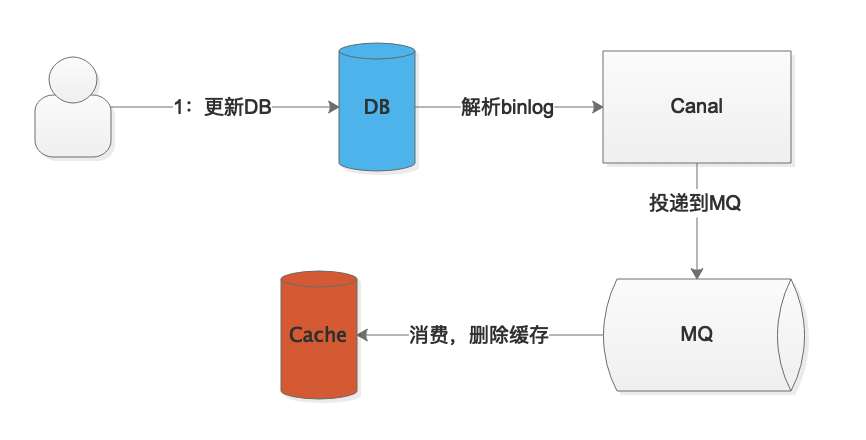
这里引入了2个中间件,系统的复杂度提升了,缓存的删除会有所延迟,但是可以保证最终的数据一致性。
最后
Cache和DB的数据一致性问题是很难根除的,我们只能减少数据不一致的时间窗,来达到最终的数据一致性。
如果我们可以接受短时间内数据的不一致,可以采用方案2,先更新DB,然后删除Cache,同时增加删除失败的重试策略,缓存的过期时间可以设置短点。
如果我们要求数据的强一致性,那么就要牺牲系统的可用性,可以把更新DB和删除Cache两个操作放在一个事务里,要么同时成功,要么同时失败。
如果我们是在高并发场景,同时要考虑到极端情况,保证最终的数据一致性,那么我们就要引入Canal来解析binglog,同时投递到MQ,消费消费删除Cache。
所以,最终的设计方案需要根据场景来选择。